
Что такое NPS и как этот показатель помогает в управлении репутацией (SERM)
Представьте: вы ищете хорошего стоматолога или надежный сервис по ремонту авто. Первое, что делаете – спрашиваете у друзей или читаете отзывы в интернете. Рекомендация – один из инструментов выбора товара или услуги. А можно ли измерить ее силу для бизнеса, предсказать рост и управлять своей репутацией не на ощупь, а используя данные?
Что такое NPS?
Net Promoter Score (NPS) – это индекс потребительской лояльности. Он показывает, сколько у вас «адвокатов бренда», готовых его рекомендовать, и сколько «недоброжелателей», которые могут его ругать.
Вся система строится на одном ключевом вопросе, который задают клиентам после сделки, обслуживания или через определенный промежуток времени:
«По шкале от 0 до 10, насколько вероятно, что вы порекомендуете нашу компанию/услугу/продукт другу или коллеге?»
На основе ответов всех клиентов формируется одна итоговая оценка от -100 до +100. Но чтобы ее получить, нужно сначала разделить клиентов на три группы.
Три типа клиентов: кто они и почему это важно

Как рассчитать NPS: простая математика
Проведите опрос и подсчитайте процентное соотношение
Промоутеров и Критиков от общего числа ответивших.
Формула: NPS = (% Промоутеров) – (% Критиков)
Пример расчета:
Вы опросили 100 клиентов.
-
Промоутеры (9-10 баллов): 50 человек → 50%.
-
Нейтралы (7-8 баллов): 30 человек → 30% (не участвуют в расчете).
-
Критики (0-6 баллов): 20 человек → 20%.
Ваш NPS = 50% — 20% = 30.
Шкала оценки результата:
-
-100 до 0. Зона риска. Недовольных клиентов больше, чем лояльных. Серьезные проблемы с продуктом или сервисом. Репутация под угрозой.
-
0 до 30. Норма. Средний показатель для многих рынков. Есть база, но и много работы.
-
30 до 70. Хорошо и отлично. Вы делаете многое правильно, у вас больше сторонников, чем критиков. Это сильное конкурентное преимущество.
-
70 до 100. Великолепно. Выдающийся результат. У вас армия лояльных клиентов, которые двигают бизнес за счет сарафанного радио.
Инструменты для старта
Пример NPS-опроса (после оказания услуги / доставки товара)
Тема письма: [Имя], поделитесь впечатлениями о покупке?
Текст письма:
«Здравствуйте, [Имя]!
Нам важно ваше мнение о нашей работе. Это поможет нам стать лучше.
По шкале от 0 до 10, насколько вероятно, что вы порекомендуете нас другу или коллеге?
[Шкала от 0 до 10 с кнопками для выбора]
Пожалуйста, расскажите, почему вы выбрали именно эту оценку?
[Поле для свободного текстового ответа]
Спасибо за ваше время! Ваш отзыв очень ценен для нас».
Таблица для анализа и планирования действий по результатам NPS
Для анализа NPS удобно использовать Excel или Google Таблицы. С их помощью:
-
легко сегментировать клиентов по группам;
-
автоматически рассчитывать процент промоутеров и критиков;
-
отслеживать динамику.
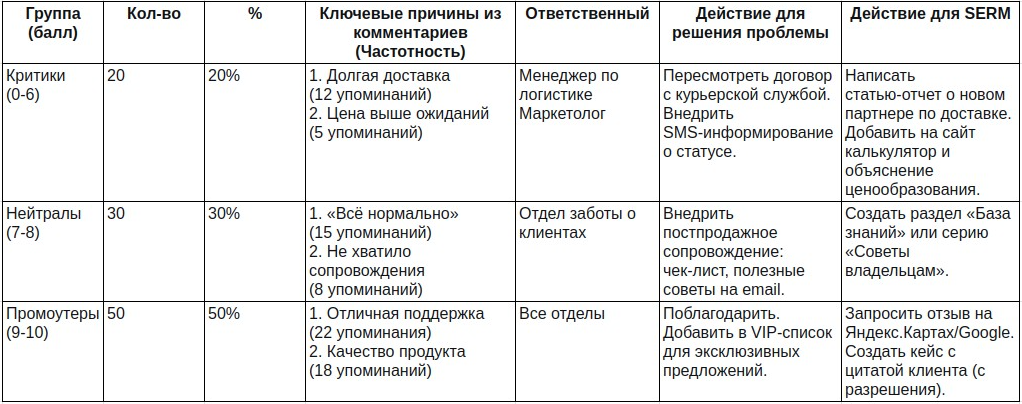
NPS + SERM = Стратегия управления репутацией, основанная на данных
Теперь, когда мы уже разобрались, что такое NPS, разберемся с тем, как это интегрировать в полноценную репутационную стратегию.
SERM (Search Engine Reputation Management) – это управление тем, что видят о вас люди в поиске Google и Яндекс.
Цель – чтобы по запросу «[Ваша компания] отзывы» люди видели позитивный или нейтральный контент, а не море негатива.
Казалось бы, SERM – это про ответы на отзывы и публикация хороших новостей и успешных кейсов. Но без NPS зачастую – это стрельба вслепую. NPS помогает собирать важные данные и отвечает на вопросы: Кто? Почему? И что делать в первую очередь?
Практическая связка: как использовать NPS для усиления SERM
1. Предотвращайте негатив до его появления
Задача — решить проблему до того, как о ней станет известно другим потенциальным клиентам в интернете. Получив оценку 0-6 и комментарий от Критика, у вас есть уникальное окно возможностей.
-
Что делать: внедрите триггерную рассылку. Клиент поставил 1-6 баллов → автоматически его письмо попадает к персональному менеджеру или в специальный отдел поддержки с задачей немедленно связаться. Цель — решить проблему лично, не давая ей выплеснуться на публичную площадку.
-
Эффект для SERM: вы проактивно уменьшаете поток потенциального негатива в интернете.
2. Мотивируйте «промоутеров» оставлять отзывы
Это ваши самые горячие фанаты. Они уже сказали, что готовы рекомендовать ваш бренд другим пользователям. Помогите им это сделать там, где это будет видно всем.
-
Что делать: настройте автоматизацию. Клиент поставил 9-10 баллов → тут же получает письмо: «Спасибо за высокую оценку! Поделитесь, пожалуйста, вашим опытом на [Яндекс.Карты / Google Карты / 2ГИС]. Ваш отзыв поможет другим сделать правильный выбор» + прямая ссылка.
-
Эффект для SERM: вы генерируете поток органических позитивных отзывов. Это самое ценное для поисковиков и для доверия пользователей. Такие отзывы вытесняют негатив в поисковой выдаче.
3. Создавайте контент на основе жалоб
Поле «Почему вы поставили такую оценку?» — это «золотая жила» для SERM-специалиста.
-
Шаг 1. Анализ: соберите все комментарии «критиков» в таблицу. Выделите повторяющиеся темы (например, «долгая доставка», «непонятная инструкция», «высокая цена»).
-
Шаг 2. Действие для SERM: по каждой частой проблеме создайте обучающий или разъясняющий контент.
Например:
Проблема «долгая доставка» → статья в блоге «Как мы изменили логистику, чтобы доставлять заказы за 24 часа» + FAQ на сайте с актуальными сроками.
Проблема «непонятная инструкция» → серия коротких видеоинструкций на YouTube и в соцсетях.
-
Эффект: этот полезный контент начинает ранжироваться в поиске. Человек, который ищет «[Ваш продукт] сложная настройка», найдет ваше видео, а не гневный отзыв на форуме.
Заключение: от реакции к управлению
Без NPS работа с репутацией (SERM) часто сводится к реакции на уже случившееся: ответ на плохой отзыв, публикация новости для вытеснения негатива.
Внедрив NPS, вы переходите в режим стратегического управления репутацией:
-
Вы измеряете лояльность и получаете честные данные.
-
Вы анализируете и находите коренные причины проблем.
-
Вы действуете прицельно: спасаете Критиков, мотивируете Промоутеров и создаете контент, который заранее закрывает «болевые точки».
Итоговый Net Promoter Score — это не просто красивая цифра для отчета. Это компас, который показывает, куда двигаться, чтобы ваша репутация в поиске стала естественным следствием отличного клиентского опыта.
Оригинал статьи на SEOnews


