
Как составить правильный robots.txt для Яндекса и Google. Инструкция
Реклама. ООО «Клик.ру», ИНН:7743771327, ERID: 2VtzqubSg4i
Когда поисковые системы сканируют сайт, они действуют по собственным алгоритмам и не всегда обходят страницы так, как нужно владельцу ресурса. В результате в выдаче могут появляться технические URL, фильтры, дубль-контент или временные страницы, которые не предназначены для пользователей. Чтобы направить роботов и управлять тем, что действительно попадает в индекс, используется файл robots.txt – небольшой, но критически важный инструмент технической оптимизации.
Несмотря на простую структуру, robots.txt способен решить сразу несколько задач: снизить нагрузку на сервер, оптимизировать краулинговый бюджет, защитить поисковую выдачу от «мусорных» страниц и помочь поисковикам быстрее добраться до ключевых разделов сайта. Но только при условии, что файл составлен без ошибок и уважает правила, по которым работают краулеры.
В этом материале мы разберемся, как формируется robots.txt, какие директивы используют разные CMS, какие ошибки встречаются чаще всего и как обеспечить корректную работу файла на любых платформах.
Для чего нужен robots.txt
Файл robots.txt служит точкой взаимодействия сайта с поисковыми роботами Google и Яндекса. Через него владелец ресурса сообщает краулерам, какие разделы можно просматривать, а какие лучше пропускать. По сути, это набор директив, которые помогают управлять индексацией: бот получает рекомендации, какие URL сканировать, а какие страницы не трогать вовсе.
Если поисковая система учтет эти указания, в обход пойдут лишние дубли, технические URL, страницы с GET-параметрами и прочие материалы, не представляющие ценности для пользователя.
Обычно в robots.txt ограничивают доступ к:
-
сервисным разделам;
-
неинформативным URL;
-
дублям;
-
страницам, формирующимся динамически.
Это делается для того, чтобы:
-
снизить нагрузку на сервер за счет уменьшения количества запросов роботов;
-
рационально расходовать краулинговый бюджет – объем URL, которые поисковик способен просканировать за одну сессию;
-
защитить поисковую выдачу от попадания неподходящих страниц.
Как закрыть страницу от поисковых ботов
Важно понимать: правила в robots.txt – не приказы, а рекомендации. Даже если URL запрещен для сканирования, он все равно может оказаться в выдаче, если на него ведут внутренние или внешние ссылки. В этом случае карточка такого URL будет отображаться без сниппета: бот увидит сам факт существования страницы, но не сможет прочитать ее содержимое.

Если необходимо полностью исключить страницу из индекса, одного запрета в robots.txt мало.
Надежные способы:
-
Ограничить доступ по паролю. Для служебных разделов это оптимальный вариант. Если контент закрыт авторизацией, краулер физически не сможет получить доступ.
Использовать метатеги noindex и nofollow. Подключают их внутри блока < head >:
< meta name="robots" content="noindex, nofollow"/ >
-
В этом случае робот поймет, что страницу индексировать нельзя, а ссылки на ней – не учитывать.
Главный нюанс: не закрывайте такую страницу одновременно через robots.txt. Если робот не сможет зайти на URL, он не увидит метатеги и проигнорирует запрет.
Требования поисковых систем к robots.txt
Google и Яндекс предъявляют практически одинаковые требования к оформлению и размещению файла:
-
Формат: исключительно .txt.
-
Размер: до 32 КБ.
-
Название: строго строчными буквами – robots.txt. Измененный регистр поисковики не распознают.
-
Язык записи: вся структура – только латиницей. Исключение – домены на кириллице; их необходимо переводить в punycode (например, «окна.рф» → xn--80atjc.xn--p1ai).
-
Комментарии: можно писать на любом языке, так как они не анализируются ботами. Для комментариев используется символ #.
-
Количество: должен существовать один общий robots.txt для домена и его поддоменов.
-
Размещение: только в корневом каталоге сайта. При наличии поддоменов – файл нужно положить отдельно в корень каждого из них.
-
Доступность: файл должен корректно открываться по адресу https://example.com/robots.txt и отдавать код 200 OK.
Подробные гайды доступны в официальных справках Яндекса и Google.
Как грамотно сформировать robots.txt
Файл robots.txt – это набор инструкций, которые сообщают поисковым роботам, какие разделы сайта можно просматривать, а какие лучше игнорировать. Каждая директива применяется к конкретным ботам, указанным в строке User-agent, и определяет правила доступа для выбранных частей ресурса.
Хотя набор команд для Яндекса и Google в последние годы стал практически одинаковым, у Яндекса все еще есть своя особенность – директива Clean-param, предназначенная для борьбы с дублями, возникающими из-за GET-параметров.
Основные директивы и что они значат
User-agent
Через эту команду определяется адресат. После двоеточия записывают имя конкретного бота или символ *, если правила должны применяться ко всем.
Примеры:
-
User-agent: * – инструкции для всех поисковых роботов.
-
User-agent: Googlebot – команды только для Googlebot.
Disallow
Эта директива блокирует сканирование определенных страниц или разделов. После наклонной черты указывают путь, который должен быть закрыт.

Пустой Disallow: означает, что сайт полностью открыт для обхода. А запись Disallow: / запрещает роботам просматривать сайт целиком – важно убедиться, что такой запрет случайно не останется в файле после разработки нового проекта.
Можно управлять доступом избирательно. Например, разрешить только Googlebot просканировать сайт, но ограничить остальных роботов:

Наличие или отсутствие косой черты меняет смысл директивы.
-
Disallow: /about/ – закрывает только раздел «О нас».
-
Disallow: /about – блокирует все URL, начинающиеся с /about, включая вложенные страницы.
Каждая директива записывается отдельной строкой – перечислять несколько запретов подряд в одной записи нельзя.
Allow
Используется для точечного открытия отдельных URL. Например, если целиком раздел закрыт, но одно конкретное изображение должно индексироваться:

Clean-param – специальная директива Яндекса
Эта команда помогает бороться с дублями, которые возникают при использовании UTM-меток или случайных параметров. Google ее не учитывает, поэтому при необходимости можно заменить Clean-param на Disallow.
Например, если у страницы есть URL:
https://example.com/index.php?page=1&sid=2564126ebdec301c607e5df
https://example.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
Или аналогичные ссылки с параметрами, которые не влияют на содержимое страницы, структура в robots.txt будет такой:
Clean-param: sid /index.php
Если параметров несколько, их перечисляют через амперсанд:
Clean-param: sid&utm&ref /index.php
Строка не должна превышать 500 символов, но при большом количестве параметров правило можно разбить на несколько более коротких.
Sitemap в robots.txt
Если на сайте есть карта сайта, ее путь можно указать через директиву Sitemap – поисковым роботам так проще ориентироваться в структуре ресурса:
Sitemap: https://example.com/sitemap.xml
Спецсимволы в robots.txt
-
* – подставляет любую последовательность символов.
-
$ – указывает, что правило действует только при совпадении конца URL.
Например:
Disallow: /catalog/category1$
Такая команда запретит доступ к разделу /catalog/category1, но оставит открытым просмотр товаров внутри него.
Зачем использовать генераторы robots.txt
Собирать файл вручную не обязательно. Существуют бесплатные онлайн-инструменты, которые помогают автоматически сформировать robots.txt: указать путь к sitemap, закрыть или открыть разделы, добавить ограничения для краулеров и настроить интервал посещений.
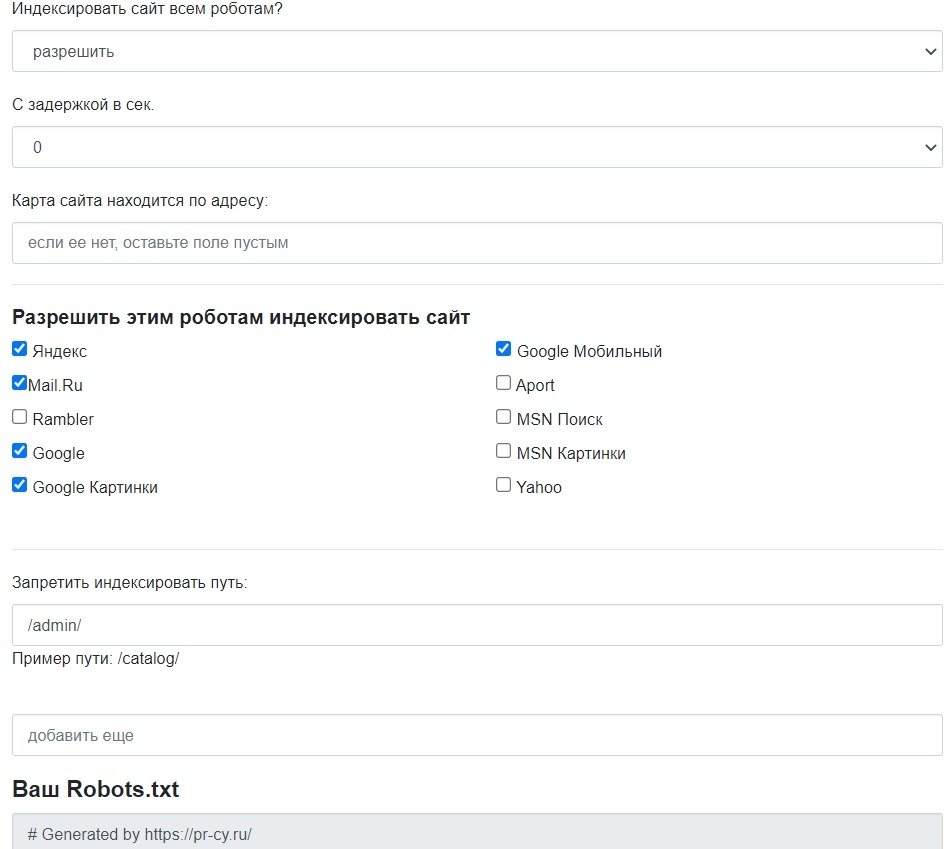
Для популярных CMS есть плагины, позволяющие управлять robots.txt прямо из админки.
Как убедиться, что robots.txt работает корректно
После размещения файла в корневом каталоге сайта важно проверить, как его видят поисковые системы. Для этого существуют специальные инструменты:
-
Проверка robots от Яндекса – позволяет выявить ошибки в структуре и содержимом.
-
Robots Tester от Google – помогает оценить доступность файла и корректность настроек.
-
PR-CY Анализ сайта – показывает наличие robots.txt, ошибки индексации и множество других технических параметров – дата обновления файла, статус доступности, найденные предупреждения и рекомендации.
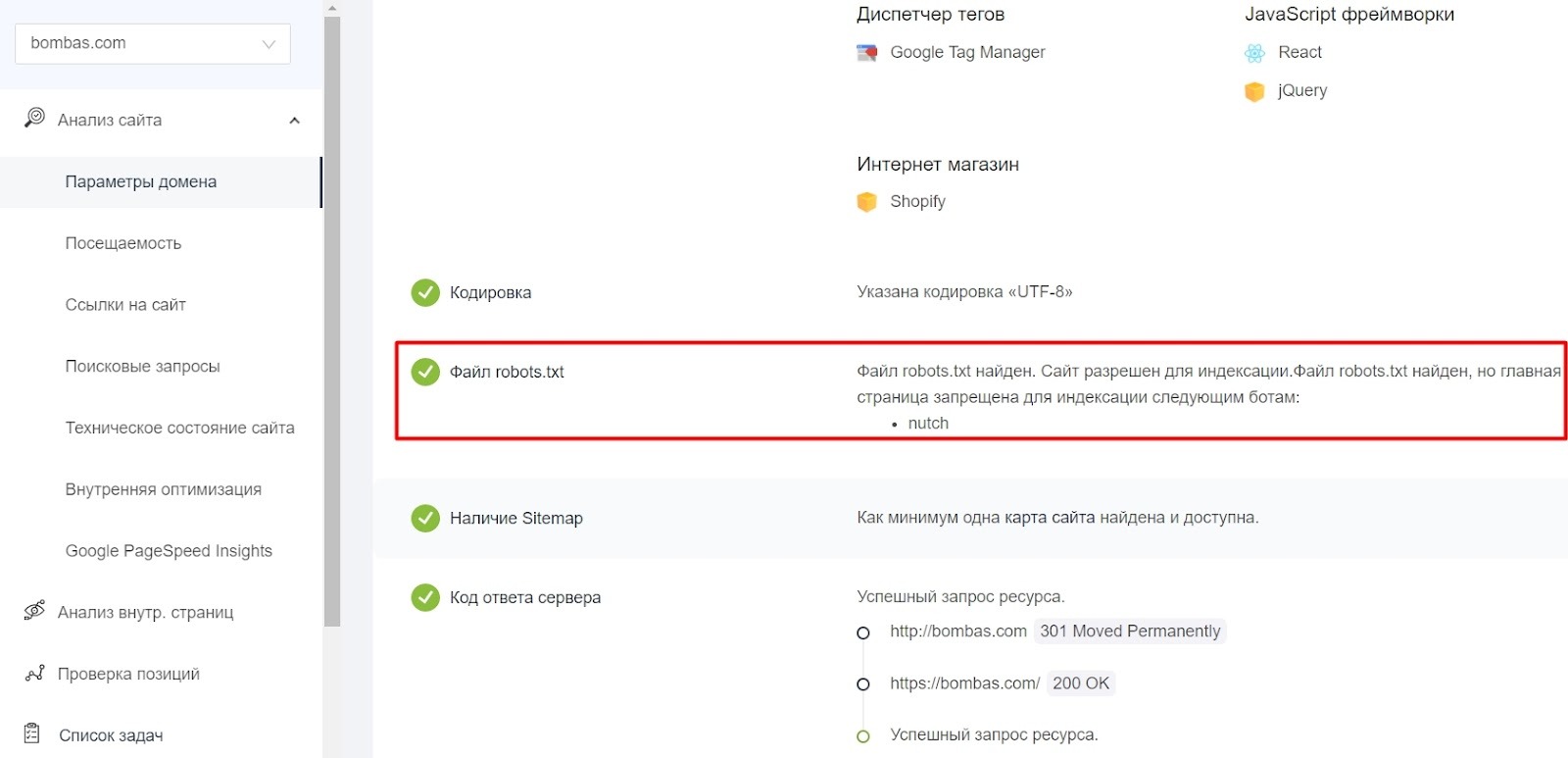
Готовые варианты robots.txt для популярных CMS
Файл robots.txt располагается в корне сайта и редактируется либо через FTP-доступ, либо через встроенные инструменты CMS (если они предусмотрены). Некоторые системы управления позволяют работать с файлом прямо из админки, что упрощает процесс настройки. Рассмотрим, какие возможности дают популярные движки и какие примеры файлов подходят для разных типов сайтов.
WordPress
В экосистеме WordPress есть множество плагинов, позволяющих автоматически формировать или изменять robots.txt. Такая функция встроена в крупные SEO-плагины Yoast SEO и All in One SEO, но существуют и узкоспециализированные решения – например:
-
Virtual Robots.txt
-
WordPress Robots.txt optimization (+XML Sitemap)
Пример robots.txt для контентного проекта на WordPress
Это базовая версия файла, подходящая для блогов и информационных сайтов, где нет личного кабинета, корзины или других e-commerce элементов.

Пример robots.txt для интернет-магазина на WordPress
Если сайт работает на WooCommerce, к стандартным правилам добавляют запрет на индексацию:
-
корзины;
-
страницы оформления заказа;
-
URL добавления товара в корзину.

Таким образом, поисковики не будут обходить технические страницы, которые не должны появляться в выдаче.
1C-Битрикс
В Битриксе можно управлять robots.txt прямо из панели администратора, начиная с версии 14.0.0. Настройки находятся в разделе:
Маркетинг → Поисковая оптимизация → Настройка robots.txt
Пример robots.txt для сайта на Битрикс
В файле обычно указывают стандартный набор запретов, но добавляют учет личных кабинетов, что характерно для большинства проектов на этой CMS.

OpenCart
Для OpenCart существует официальный модуль, позволяющий редактировать robots.txt без FTP.
Пример robots.txt для магазина на OpenCart
Так как OpenCart чаще всего используется для интернет-магазинов, правила ориентированы на e-commerce: закрываются аккаунт, корзина, поиск, параметры сортировки, фильтры и другие технические URL.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: *page=*
Disallow: *search=*
Disallow: /cart/
Disallow: /forgot-password/
Disallow: /login/
Disallow: /compare-products/
Disallow: /add-return/
Disallow: /vouchers/
Sitemap: https://example.com/sitemap.xml
Joomla
В Joomla система сама создает robots.txt при установке и сразу включает необходимые запреты. Отдельные расширения для генерации файла не требуются.
Пример robots.txt для сайта на Joomla
Чаще всего закрывают служебные каталоги, шаблоны, плагины, модули и другие элементы, которые не должны быть доступны поисковикам.
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
Sitemap: https://example.com/sitemap.xml
Поисковики рассматривают правила в robots.txt как рекомендации. Если в файле нет противоречий и на закрытые URL не ведут ссылки, то вероятность игнорирования директив минимальна. Грамотно настроенный robots.txt помогает избежать утечки технических страниц в выдачу и экономит краулинговый бюджет.
Как PromoPult помогает с настройкой robots.txt
Перед стартом продвижения SEO-модуль PromoPult автоматически проверяет техническое состояние сайта, включая robots.txt, и формирует чек-лист задач по внутренней оптимизации. Исправления можно выполнить самостоятельно, передать сотрудникам или поручить специалистам платформы.
Благодаря AI-инструментам PromoPult многие сложные процессы автоматизированы: система анализирует семантику, проводит техническую диагностику, подсказывает ошибки и формирует рекомендации. Протестировать SEO в сервисе можно бесплатно в течение 14 дней, а успешные кейсы из вашей ниши – посмотреть в подборке.
Оригинал статьи на SEOnews


